Publications
publications by categories in reversed chronological order.
2024
- ICML Workshop
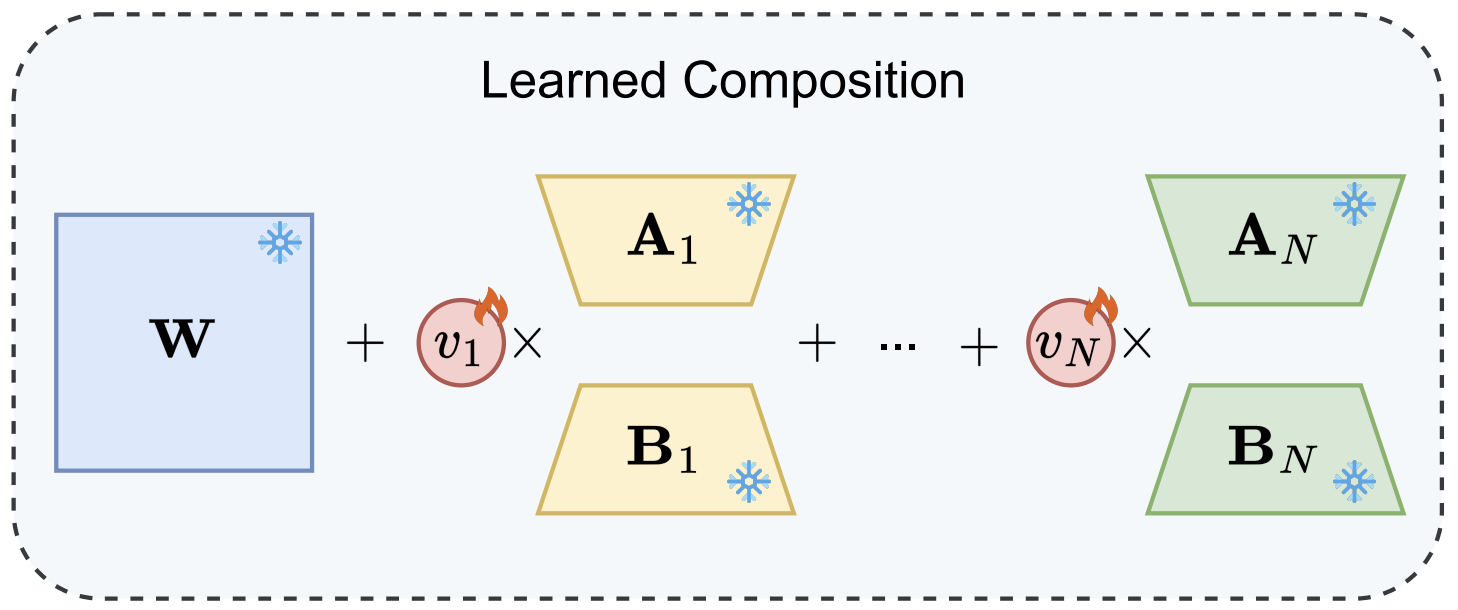 Does Combining Parameter-efficient Modules Improve Few-shot Transfer Accuracy?Nader Asadi, Mahdi Beitollahi, Yasser Khalil, Yinchuan Li, Guojun Zhang, and Xi ChenIn ICML Workshop, 2024
Does Combining Parameter-efficient Modules Improve Few-shot Transfer Accuracy?Nader Asadi, Mahdi Beitollahi, Yasser Khalil, Yinchuan Li, Guojun Zhang, and Xi ChenIn ICML Workshop, 2024@inproceedings{asadi2024does, title = {Does Combining Parameter-efficient Modules Improve Few-shot Transfer Accuracy?}, author = {Asadi, Nader and Beitollahi, Mahdi and Khalil, Yasser and Li, Yinchuan and Zhang, Guojun and Chen, Xi}, booktitle = {ICML Workshop}, year = {2024}, } - TMLR
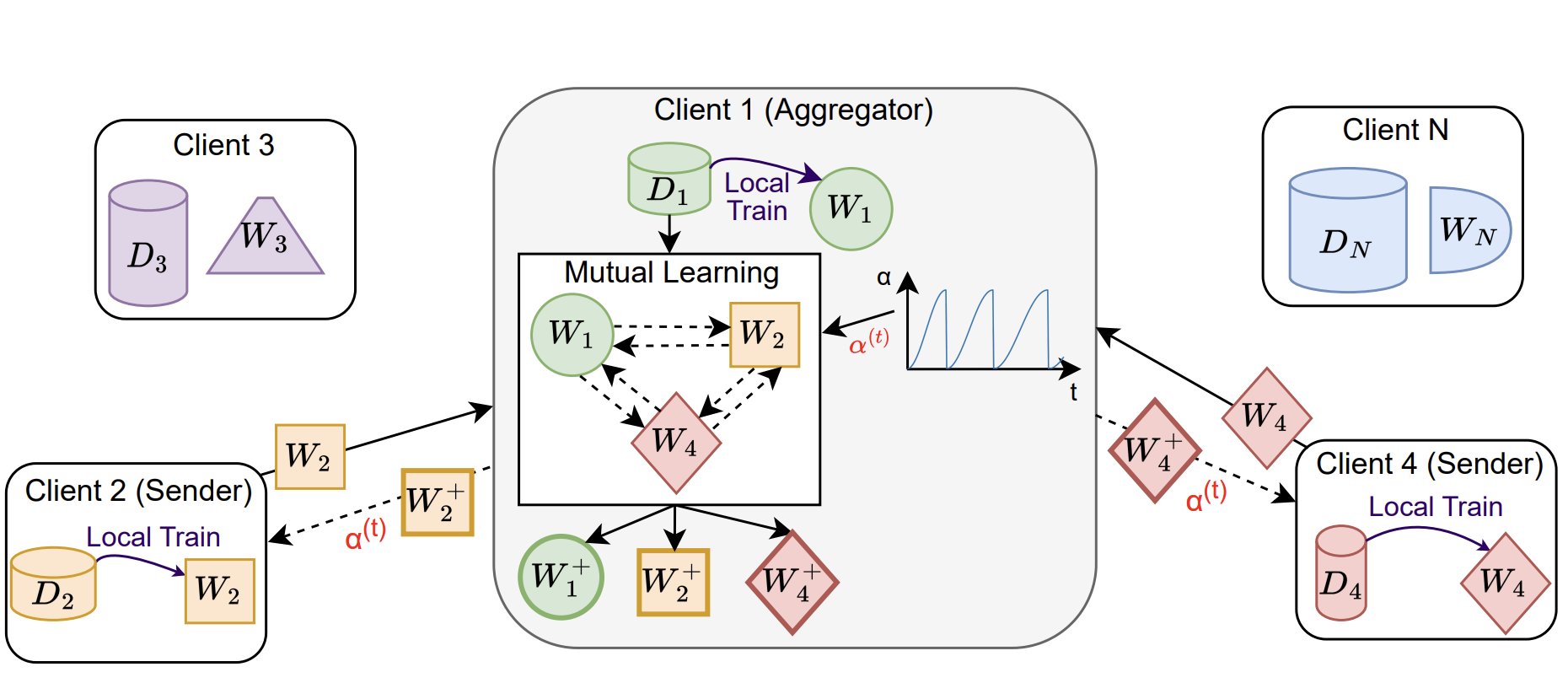 DFML: Decentralized Federated Mutual LearningYasser Khalil, Amir Estiri, Mahdi Beitollahi, Nader Asadi, Sobhan Hemati, Xu Li, and 2 more authorsIn TMLR, 2024
DFML: Decentralized Federated Mutual LearningYasser Khalil, Amir Estiri, Mahdi Beitollahi, Nader Asadi, Sobhan Hemati, Xu Li, and 2 more authorsIn TMLR, 2024@inproceedings{khalil2024dfml, title = {DFML: Decentralized Federated Mutual Learning}, author = {Khalil, Yasser and Estiri, Amir and Beitollahi, Mahdi and Asadi, Nader and Hemati, Sobhan and Li, Xu and Zhang, Guojun and Chen, Xi}, booktitle = {TMLR}, year = {2024}, }


2023
- Preprint
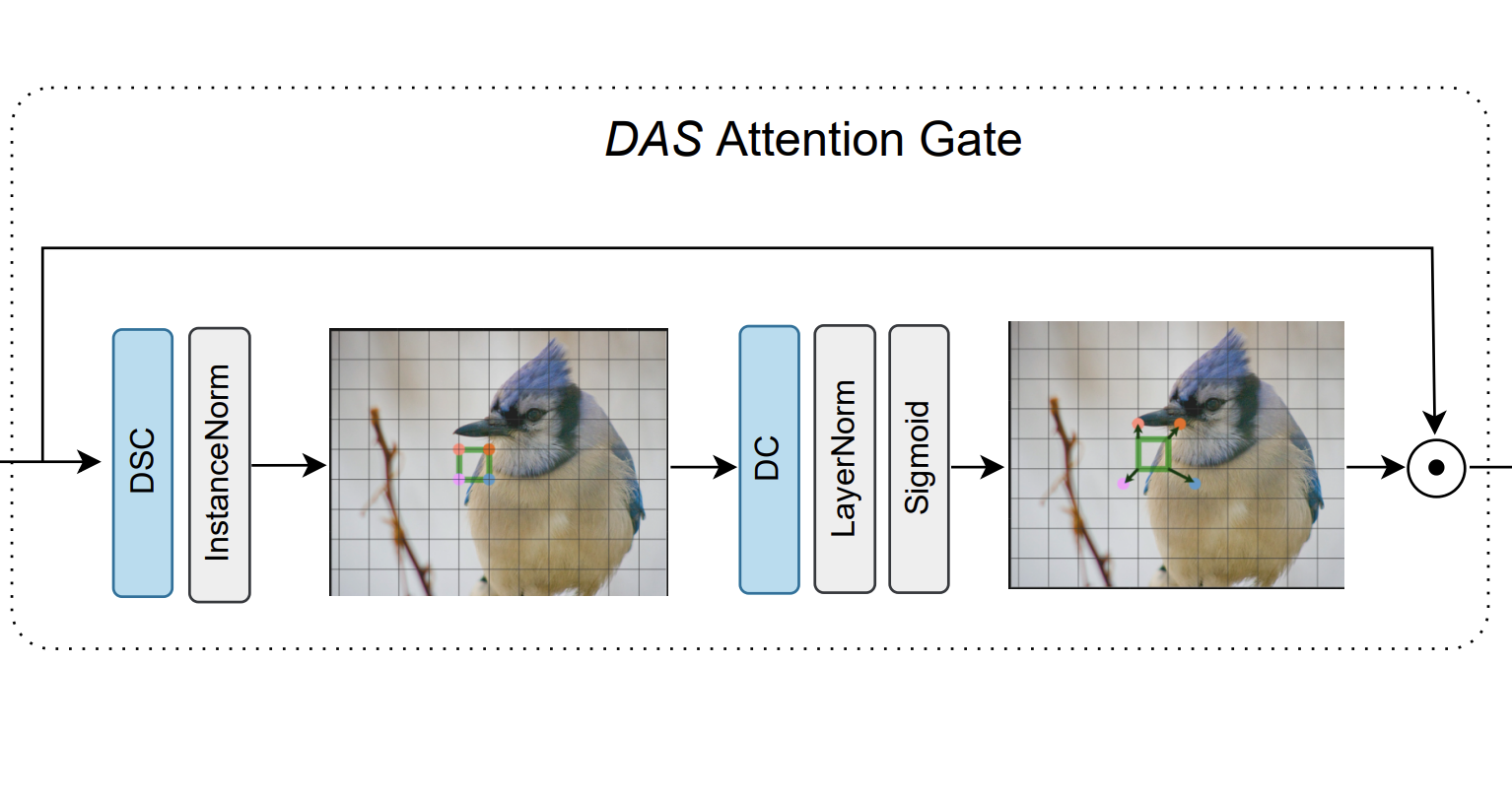 DAS: A Deformable Attention to Capture Salient Information in CNNsFarzad Salajegheh, Nader Asadi, Soroush Saryazdi, and Sudhir MudurIn Preprint, 2023
DAS: A Deformable Attention to Capture Salient Information in CNNsFarzad Salajegheh, Nader Asadi, Soroush Saryazdi, and Sudhir MudurIn Preprint, 2023@inproceedings{salajegheh2023das, title = {DAS: A Deformable Attention to Capture Salient Information in CNNs}, author = {Salajegheh, Farzad and Asadi, Nader and Saryazdi, Soroush and Mudur, Sudhir}, booktitle = {Preprint}, year = {2023}, } - ICML
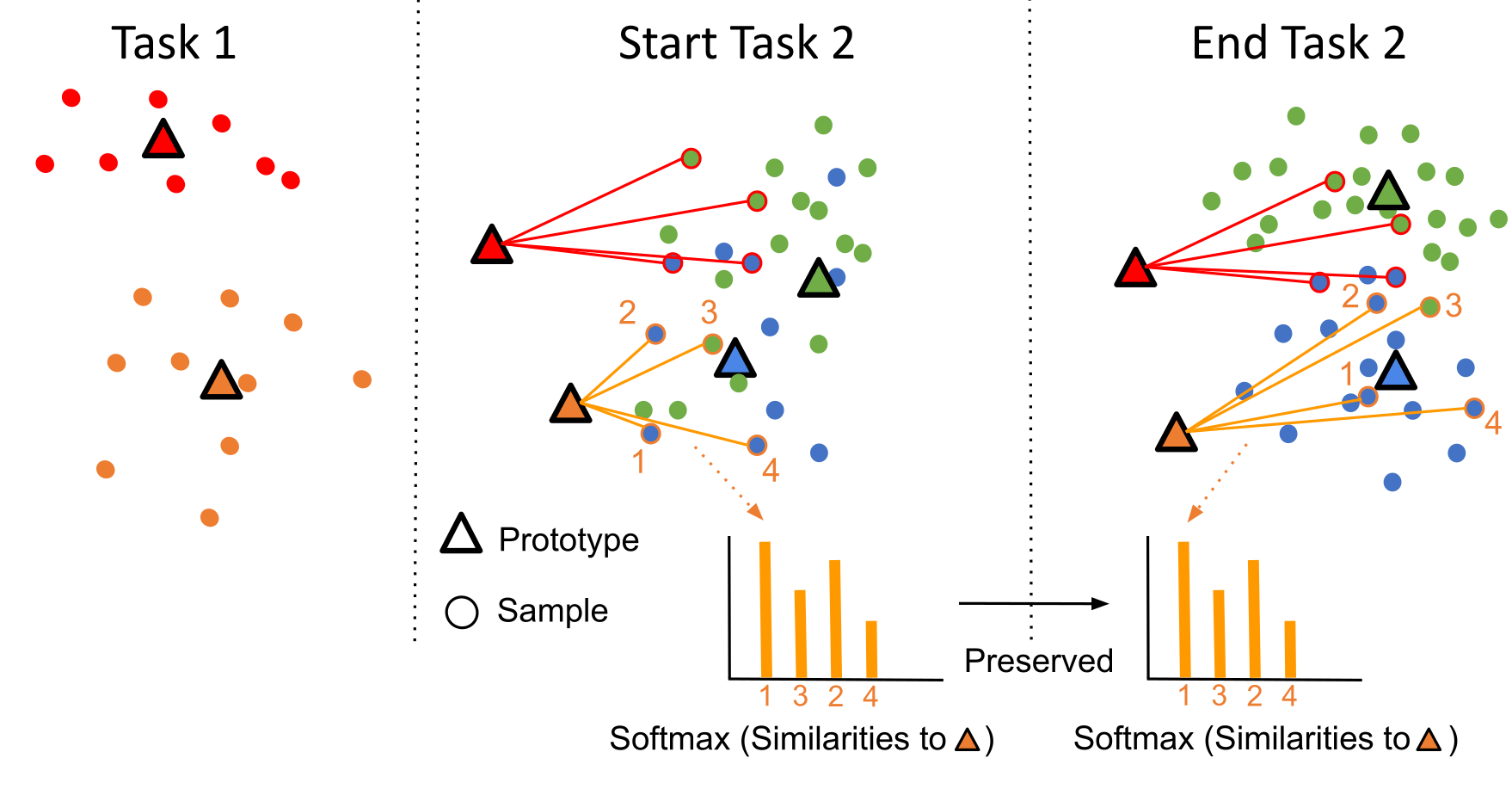 Prototype-Sample Relation Distillation: Towards Replay-Free Continual LearningNader Asadi, MohammadReza Davari, Sudhir Mudur, Rahaf Aljundi, and Eugene BelilovskyIn ICML, 2023
Prototype-Sample Relation Distillation: Towards Replay-Free Continual LearningNader Asadi, MohammadReza Davari, Sudhir Mudur, Rahaf Aljundi, and Eugene BelilovskyIn ICML, 2023In Continual learning (CL) balancing effective adaptation while combating catastrophic forgetting is a central challenge. Many of the recent best-performing methods utilize various forms of prior task data, e.g. a replay buffer, to tackle the catastrophic forgetting problem. Having access to previous task data can be restrictive in many real-world scenarios, for example when task data is sensitive or proprietary. To overcome the necessity of using previous tasks data, in this work, we start with strong representation learning methods that have been shown to be less prone to forgetting. We propose a holistic approach to jointly learn the representation and class prototypes while maintaining the relevance of old class prototypes and their embedded similarities. Specifically, samples are mapped to an embedding space where the representations are learned using a supervised contrastive loss. Class prototypes are evolved continually in the same latent space, enabling learning and prediction at any point. To continually adapt the prototypes without keeping any prior task data, we propose a novel distillation loss that constrains class prototypes to maintain relative similarities as compared to new task data. This method yields state-of-the-art performance in the task-incremental setting where we are able to outperform other methods that both use no data as well as approaches relying on large amounts of data. Our method is also shown to provide strong performance in the class-incremental setting without using any stored data points.
@inproceedings{asadi2023towards, title = {Prototype-Sample Relation Distillation: Towards Replay-Free Continual Learning}, author = {Asadi, Nader and Davari, MohammadReza and Mudur, Sudhir and Aljundi, Rahaf and Belilovsky, Eugene}, booktitle = {ICML}, year = {2023}, }


2022
- CVPR
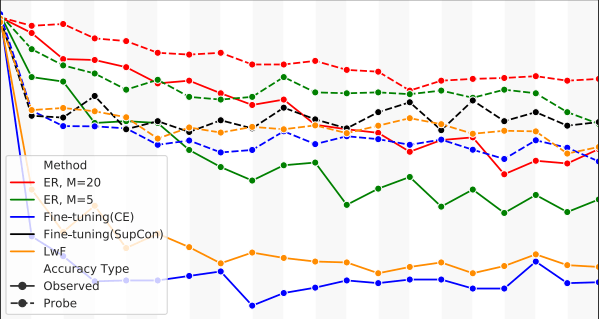 Probing Representation Forgetting in Supervised and Unsupervised Continual LearningMohammadReza Davari, Nader Asadi, Sudhir Mudur, Rahaf Aljundi, and Eugene BelilovskyIn CVPR, 2022
Probing Representation Forgetting in Supervised and Unsupervised Continual LearningMohammadReza Davari, Nader Asadi, Sudhir Mudur, Rahaf Aljundi, and Eugene BelilovskyIn CVPR, 2022Continual Learning (CL) research typically focuses on tackling the phenomenon of catastrophic forgetting in neural networks. Catastrophic forgetting is associated with an abrupt loss of knowledge previously learned by a model when the task, or more broadly the data distribution, being trained on changes. In supervised learning problems this forgetting, resulting from a change in the model’s representation, is typically measured or observed by evaluating the decrease in old task performance. However, a model’s representation can change without losing knowledge about prior tasks. In this work we consider the concept of representation forgetting, observed by using the difference in performance of an optimal linear classifier before and after a new task is introduced. Using this tool we revisit a number of standard continual learning benchmarks and observe that, through this lens, model representations trained without any explicit control for forgetting often experience small representation forgetting and can sometimes be comparable to methods which explicitly control for forgetting, especially in longer task sequences. We also show that representation forgetting can lead to new insights on the effect of model capacity and loss function used in continual learning. Based on our results, we show that a simple yet competitive approach is to learn representations continually with standard supervised contrastive learning while constructing prototypes of class samples when queried on old samples.
@inproceedings{davari2022probing, title = {Probing Representation Forgetting in Supervised and Unsupervised Continual Learning}, author = {Davari, MohammadReza and Asadi, Nader and Mudur, Sudhir and Aljundi, Rahaf and Belilovsky, Eugene}, booktitle = {CVPR}, year = {2022}, equal_first_authors = {Davari, MohammadReza and Asadi, Nader}, } - ICLR
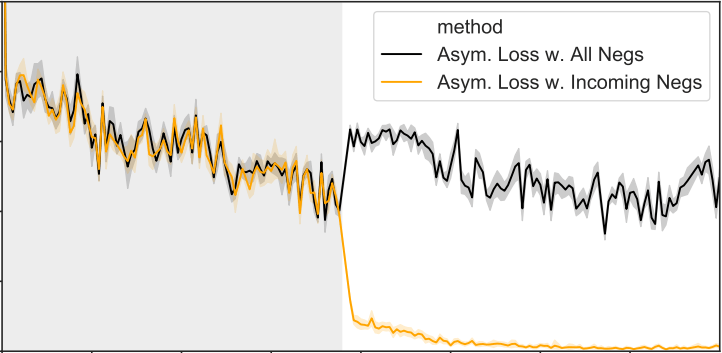 New Insights on Reducing Abrupt Representation Change in Online Continual LearningLucas Caccia, Rahaf Aljundi, Nader Asadi, Tinne Tuytelaars, Joelle Pineau, and Eugene BelilovskyIn ICLR, 2022
New Insights on Reducing Abrupt Representation Change in Online Continual LearningLucas Caccia, Rahaf Aljundi, Nader Asadi, Tinne Tuytelaars, Joelle Pineau, and Eugene BelilovskyIn ICLR, 2022In the online continual learning paradigm, agents must learn from a changing distribution while respecting memory and compute constraints. Experience Replay (ER), where a small subset of past data is stored and replayed alongside new data, has emerged as a simple and effective learning strategy. In this work, we focus on the change in representations of observed data that arises when previously unobserved classes appear in the incoming data stream, and new classes must be distinguished from previous ones. We shed new light on this question by showing that applying ER causes the newly added classes’ representations to overlap significantly with the previous classes, leading to highly disruptive parameter updates. Based on this empirical analysis, we propose a new method which mitigates this issue by shielding the learned representations from drastic adaptation to accommodate new classes. We show that using an asymmetric update rule pushes new classes to adapt to the older ones (rather than the reverse), which is more effective especially at task boundaries, where much of the forgetting typically occurs. Empirical results show significant gains over strong baselines on standard continual learning benchmarks.
@inproceedings{caccia2021reducing, title = {New Insights on Reducing Abrupt Representation Change in Online Continual Learning}, author = {Caccia, Lucas and Aljundi, Rahaf and Asadi, Nader and Tuytelaars, Tinne and Pineau, Joelle and Belilovsky, Eugene}, booktitle = {ICLR}, year = {2022}, }


2021
- NeurIPS Workshop
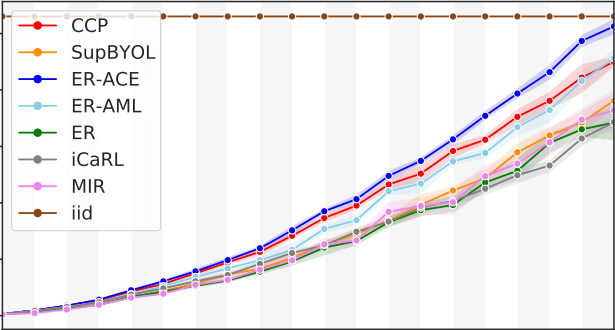 Tackling Online One-Class Incremental Learning by Removing Negative ContrastsNader Asadi, Sudhir Mudur, and Eugene BelilovskyIn NeurIPS Workshop on Distribution Shifts, 2021
Tackling Online One-Class Incremental Learning by Removing Negative ContrastsNader Asadi, Sudhir Mudur, and Eugene BelilovskyIn NeurIPS Workshop on Distribution Shifts, 2021Recent work studies the supervised online continual learning setting where a learner receives a stream of data whose class distribution changes over time. Distinct from other continual learning settings the learner is presented new samples only once and must distinguish between all seen classes. A number of successful methods in this setting focus on storing and replaying a subset of samples alongside incoming data in a computationally efficient manner. One recent proposal ER-AML achieved strong performance in this setting by applying an asymmetric loss based on contrastive learning to the incoming data and replayed data. However, a key ingredient of the proposed method is avoiding contrasts between incoming data and stored data, which makes it impractical for the setting where only one new class is introduced in each phase of the stream. In this work we adapt a recently proposed approach (\textitBYOL) from self-supervised learning to the supervised learning setting, unlocking the constraint on contrasts. We then show that supplementing this with additional regularization on class prototypes yields a new method that achieves strong performance in the one-class incremental learning setting and is competitive with the top performing methods in the multi-class incremental setting.
@inproceedings{asadi2021tackling, title = {Tackling Online One-Class Incremental Learning by Removing Negative Contrasts}, author = {Asadi, Nader and Mudur, Sudhir and Belilovsky, Eugene}, booktitle = {NeurIPS Workshop on Distribution Shifts}, year = {2021}, }

2019
- Preprint
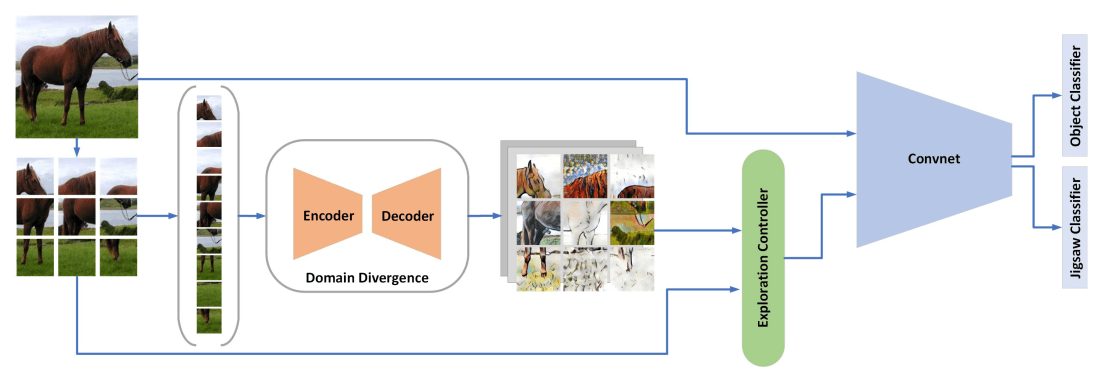 Towards shape biased unsupervised representation learning for domain generalizationNader Asadi, Amir M Sarfi, Mehrdad Hosseinzadeh, Zahra Karimpour, and Mahdi EftekhariarXiv preprint, 2019
Towards shape biased unsupervised representation learning for domain generalizationNader Asadi, Amir M Sarfi, Mehrdad Hosseinzadeh, Zahra Karimpour, and Mahdi EftekhariarXiv preprint, 2019Shape bias plays an important role in self-supervised learning paradigm. The ultimate goal in self-supervised learning is to capture a representation that is based as much as possible on the semantic of objects (i.e. shape bias) and not on individual objects’ peripheral features. This is inline with how human learns in general; our brain unconsciously focuses on the general shape of objects rather than superficial statistics of context. On the other hand, unsupervised representation learning allows discovering label-invariant features which helps generalization of the model. Inspired by these observations, we propose a learning framework to improve the learning performance of self-supervised methods by further hitching their learning process to shape bias. Using distinct modules, our method learns semantic and shape biased representations by integrating domain diversification and jigsaw puzzles. The first module enables the model to create a dynamic environment across arbitrary domains and provides a domain exploration vs. exploitation trade-off, while the second module allows it to explore this environment autonomously. The proposed framework is universally adaptable since it does not require prior knowledge of the domain of interest. We empirically evaluate the performance of our framework through extensive experiments on several domain generalization datasets, namely, PACS, Office-Home, VLCS, and Digits. Results show that the proposed method outperforms the other state-of-the-arts on most of the datasets
@article{asadi2019towards, title = {Towards shape biased unsupervised representation learning for domain generalization}, author = {Asadi, Nader and Sarfi, Amir M and Hosseinzadeh, Mehrdad and Karimpour, Zahra and Eftekhari, Mahdi}, journal = {arXiv preprint}, year = {2019}, } - NeurIPS Workshop
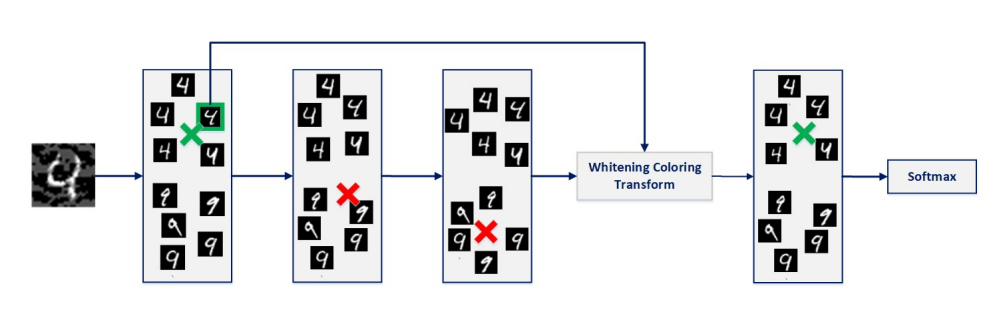 Diminishing the effect of adversarial perturbations via refining feature representationNader Asadi, AmirMohammad Sarfi, Mehrdad Hosseinzadeh, Sahba Tahsini, and Mahdi EftekhariIn NeurIPS workshop on Safety and Robustness in Decision Making, 2019
Diminishing the effect of adversarial perturbations via refining feature representationNader Asadi, AmirMohammad Sarfi, Mehrdad Hosseinzadeh, Sahba Tahsini, and Mahdi EftekhariIn NeurIPS workshop on Safety and Robustness in Decision Making, 2019Deep neural networks are highly vulnerable to adversarial examples, which imposes severe security issues for these state-of-the-art models. Many defense methods have been proposed to mitigate this problem. However, a lot of them depend on modification or additional training of the target model. In this work, we analytically investigate each layer’s representation of non-perturbed and perturbed images and show the effect of perturbations on each of these representations. Accordingly, a method based on whitening coloring transform is proposed in order to diminish the misrepresentation of any desirable layer caused by adversaries. Our method can be applied to any layer of any arbitrary model without the need of any modification or additional training. Due to the fact that full whitening of the layer’s representation is not easily differentiable, our proposed method is superbly robust against whitebox attacks. Furthermore, we demonstrate the strength of our method against some state-of-the-art black-box attacks.
@inproceedings{asadi2019diminishing, title = {Diminishing the effect of adversarial perturbations via refining feature representation}, author = {Asadi, Nader and Sarfi, AmirMohammad and Hosseinzadeh, Mehrdad and Tahsini, Sahba and Eftekhari, Mahdi}, booktitle = {NeurIPS workshop on Safety and Robustness in Decision Making}, year = {2019}, } - ICEE
 A Novel Image Perturbation Approach: Perturbing Latent RepresentationNader Asadi, and Mahdi EftekhariIn 2019 27th Iranian Conference on Electrical Engineering (ICEE), 2019
A Novel Image Perturbation Approach: Perturbing Latent RepresentationNader Asadi, and Mahdi EftekhariIn 2019 27th Iranian Conference on Electrical Engineering (ICEE), 2019


